


Es ist fantastisch, Chatgpt in der Cloud zu verwenden. Es ist immer da, verfügbar, erinnert sich an unsere vorherigen Chats und reagiert schnell und effizient. Abhängig von diesem Dienst hat auch Nachteile (Kosten, Privatsphäre), und hier tritt in eine fantastische Möglichkeit ein: Führen Sie die lokalen KI -Modelle aus. Zum Beispiel, Montieren Sie ein lokales Chatpt.
Dies konnten wir in beim Ausprobieren der neuen OpenAI Open -Modelle überprüfen. In unserem Fall wollten wir das GPT-OSS-20B-Modell ausprobieren, das theoretisch ohne allzu viele Probleme mit 16 GB Speicher verwendet werden kann.
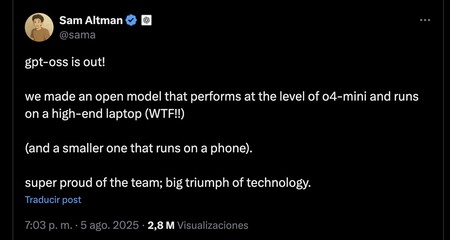
Das ist zumindest das, was Sam Altman gestern vermutete, was nach dem Start Er bestätigte Dass das obere Modell (120B) in einem Hoch -End -Laptop ausgeführt werden kann, während das kleinste auf einem Mobilgeräte ausgeführt werden kann.
Unsere Erfahrung, die zu Trompikonen gegangen ist, bestätigt diese Worte.
Erste Tests: Fehler
Nachdem ich das Modell für ein paar Stunden ausprobiert hatte, schien es mir, dass diese Aussage übertrieben war. Meine Tests waren einfach: Ich habe einen Mac Mini M4 mit 16 GB einheitlichem Gedächtnis und teste seit Monaten AI -Modelle Ollamaeine Anwendung, die es besonders einfach macht, sie zu Hause herunterzuladen und auszuführen.
In diesem Fall war der Prozess, um das neue «kleine» Modell von OpenAI zu beweisen, einfach:
- Installieren Sie Ollama in meinem Mac (ich hatte es bereits installiert)
- Begriff ein Terminal in macOS
- Laden Sie das OpenAI -Modell mit einem einfachen Befehl herunter und führen Sie sie aus: «Ollama Run GPT-OSS: 20B «
Dabei beginnt das Werkzeug dazu Laden Sie das Modell herunter, das ungefähr 13 GB wiegtdann führen Sie es bereits aus. Werfen Sie es, um es zu verwenden, um es bereits zu verwenden: Es ist erforderlich, diese 13 GB des Modells zu verschieben und sie von der Festplatte an den einheitlichen Speicher des Mac zu übergeben. Nach ein oder zwei Minuten erscheint der Indikator, dass Sie bereits mit GPT-OSS-20B schreiben und chatten können.
Dann begann ich zu versuchen, einige Dinge zu fragen, wie den traditionellen Test, Fehler zu erzählen. So bat ich das Modell, mir der Frage zu beantworten, wie viele «R» in der Phrase «San Roques Hund hat keinen Schwanz, weil Ramón Ramírez es geschnitten hat? «
Dort begann GPT-OSS-20B zu «denken» und zeigte seine Gedankenkette (Gedankenkette) in einer grauen Farbe. Dabei entdeckt man, dass dieses Modell die Frage perfekt beantwortete und sich durch Wörter trennte und dann jedes Wort unterbrochen hat, um herauszufinden, wie viele Fehler in jedem einzelnen waren. Er fügte sie am Ende hinzu und erhielt das richtige Ergebnis.
Das Problem? Das war langsam. Sehr langsam.
Nicht nur das: Bei der ersten Ausführung dieses Modells hatten zwei Firefox -Instanzen zusätzlich zu einer lockeren Sitzung in MacOS mit jeweils etwa 15 Registerkarten geöffnet. Das war ein Problem, da GPT-OSS-20B mindestens 13 GB RAM benötigt und sowohl Firefox als auch Slack und die Hintergrunddienste selbst bereits viel verbrauchen.
Das machte den Versuch, es zu benutzen, das Zusammenbruchsystem. Plötzlich wurde mein Mac Mini M4 mit 16 GB einheitliches Gedächtnis vollständig aufgehängt, ohne auf eine Klammer- oder Mausbewegung zu reagieren. Ich war tot, also musste ich es den harten neu starten. Im folgenden Neustart habe ich einfach das Terminal geöffnet, um Ollama auszuführen, und in diesem Fall konnte ich das GPT-OSS-20B-Modell verwenden, obwohl, wie ich sage, durch die Langsamkeit der Antworten begrenzt war.
Das verursachte, dass auch viele weitere Beweise auftreten konnten. Ich habe versucht, ein unwichtiges Gespräch zu beginnen, aber dort habe ich einen Fehler gemacht: Dieses Modell ist ein Argumentationsmodellund versuchen Sie daher, immer besser zu reagieren als ein Modell, das nicht argumentiert, sondern impliziert, dass es noch mehr braucht, um zu reagieren und mehr Ressourcen zu konsumieren. Und in einem solchen Team, das bereits gerade erst anfängt, ist das ein Problem.
Am Ende Gesamterfolg
Nachdem die Erfahrung in x kommentiert wurde manche Nachrichten in x Sie ermutigten mich Um es erneut zu versuchen, aber diesmal mit LM Studio, das direkt eine grafische Schnittstelle bietet, die viel mehr entspricht, mit denen Chatgpt im Browser anbietet.
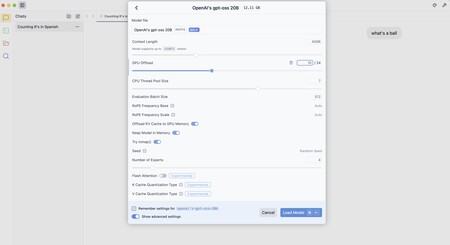
Nachdem ich es installiert und das Modell erneut heruntergeladen hatte, bereitete ich mich darauf vor, es auszuprobieren, aber als ich es versuchte, gab ich mir einen Fehler und sagte, ich hätte nicht genug Ressourcen, um das Modell zu starten. Das Problem: Der zugewiesene Grafikspeicher, der unzureichend war.
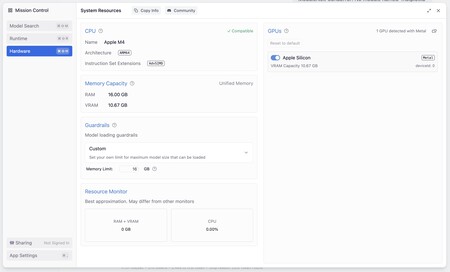
Beim Navigieren der Anwendungskonfiguration habe ich bewiesen, dass ein einheitlicher Grafikspeicher auf besondere Weise verteilt wurde und in dieser Sitzung 10.67 GB dem Grafikspeicher zugewiesen wurde.
Der Schlüssel ist, die Ausführung des Modells zu «aufhellen». Dafür ist es möglich, das Niveau des «GPU -Offloads» zu verringern – wie viele Schichten des Modells werden in der GPU geladen. Je mehr wir schneller laden, aber auch mehr grafischer Speicher verbraucht. Das Auffinden dieser Grenze in 10 war beispielsweise eine gute Option.
Es gibt andere Optionen wie das Deaktivieren von «Offload -KV -Cache in den GPU -Speicher» (Cachea Intermediate -Ergebnisse) oder die Verringerung der «Bewertungsstapelgröße», wie viele Token parallel verarbeitet werden, die wir von 512 auf 256 oder sogar 128 herunterladen können.
Sobald diese Parameter festgelegt waren, habe ich das Modell endlich im Speicher geladen (es dauert ein paar Sekunden) und kann es verwenden. Und da hat sich das Ding verändert, weil Ich habe einen Chatgpt mehr als anständig getroffen Dass er ziemlich schnell auf die Fragen beantwortete und das war im Wesentlichen sehr nutzbar.
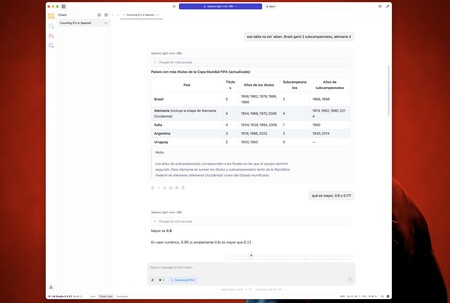
So fragte ich ihn nach dem Problem der ERRES (er antwortete perfekt) und fragte dann auch, dass er mit den fünf Ländern einen Tisch gemacht habe, den die meisten Meisterschaften und Läufer in der Welt des Fußballs gewonnen haben.
Dieser Test ist relativ einfach – die richtigen Daten Sie sind auf Wikipedia– Aber die IAS sind immer wieder falsch und das war keine Ausnahme. Einige Jahre wurden erfunden Für einige Länder und veränderte die Anzahl der Läufer, selbst als ich ihn gebeten habe, die Informationen erneut zu überprüfen.
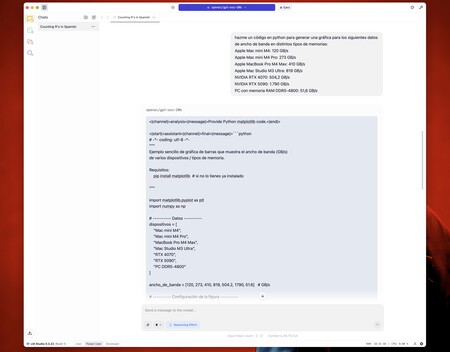
Dann wollte ich etwas anderes ausprobieren: um einen kleinen Code in Python zu generieren, um ein Diagramm aus einigen Startdaten zu erstellen. Er sagte mir, dass ich einen Buchladen (Matplotlib) installieren musste und dann den Code für das Diagramm generierte.
Es ist zu beachten, dass diese Version von «Local Chatpt» keine Bilder generiert, sondern aber Ja kann Code erstellen, der Grafiken generiertZum Beispiel, und das habe ich getan. Nachdem Sie diesen Code im Terminal ausgeführt haben, überraschen Sie. Wie Sie später sehen werden, ist das Ergebnis, obwohl etwas roh, sorpendent (und korrekt).
Die Wahrheit ist, dass die Leistung des lokalen KI -Modells mich sehr angenehm überrascht hat. Es ist wahr, dass Sie Fehler machen können, aber Wie versprechen Openai -Ingenieure Die Leistung ist der des O3-Mini-Modells sehr ähnlich, das auch bei der Verwendung in der Cloud eine großartige Option bleibt.
Die Antworten sind in der Regel sehr präzise und die Misserfolge, die Sie haben und was wir gesehen haben – die Tests waren auf einige Stunden beschränkt – stehen im Einklang mit anderen Modellen der neuesten Generation, die in Ressourcen noch fortgeschrittener und anspruchsvoller sind. Also, Mehr als angenehme Überraschung In diesen ersten Eindrücken.
Erinnerung ist alles
Das anfängliche Problem mit unseren Beweisen zeigt eine Realität: Openais Aussage und Sam Altman hat einen kleinen Druck. In der Ankündigung wird über zwei Varianten ihrer offenen KI -Modelle gesprochen. Die erste mit 120.000 Millionen Parametern (120B) und die zweite mit 20.000 Millionen (20B). Beide können kostenlos heruntergeladen und verwendet werden, aber wie wir angedeutet haben, gibt es dafür bestimmte Hardwareanforderungen.
Um diese Modelle in unseren Teams auszuführen, benötigen wir vor allem eine bestimmte Menge an Speicher:
- GPT-OSS-120B: Mindestens 80 GB Speicher
- GPT-OSS-20B: Mindestens 16 GB Speicher
Und hier ist das kritische Detail, dass diese 80 GB oder 16 GB Speicher sein sollten, vorsichtig damit, dass Grafikgedächtnis. Oder was ist das Gleiche: Um sie mit Leichtigkeit verwenden zu können, benötigen wir mindestens diese Menge an Speicher in unserer dedizierten oder integrierten GPU.
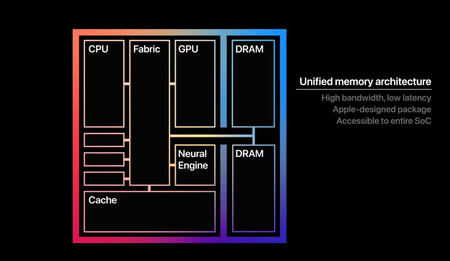
Während PCs RAM auf der einen Seite und auf dem grafischen Speicher (in der GPU, viel schneller) auf der anderen Seite verwenden, verwenden Apple Macs einen einheitlichen Speicher. Das heißt, sie «kombinieren» beide Typen und «vereinheitlichen», diesen Speicher austauschbar als Hauptspeicher oder als grafische Speicher zu verwenden.
Dieser einheitliche Speicher hat eine Leistung, die Er ist zu Pferd Zwischen dem herkömmlichen RAM, der auf Windows -PCs verwendet wird, und dem, der in den Grafikkarten der neuesten Generation vorhanden ist.
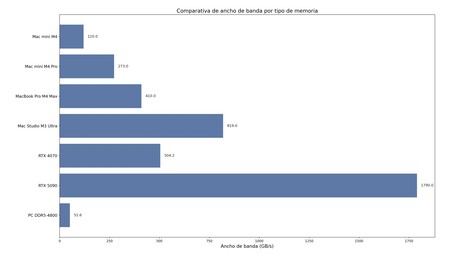
Um eine Idee zu bekommen, sind die Bandbreite einiger Apple -Chips (mit ähnlichen einheitlichen Speichersystemen, aber immer leistungsfähiger) und RAM -Erinnerungen und herkömmliche Grafiken ungefähr Folgendes:
- Apple Mac Mini M4: 120 GB/s (1)
- Apple Mac Mini M4 Pro: 273 GB/s (1)
- Apple MacBook Pro M4 max: 410 GB/s (2)
- Apple Mac Studio M3 Ultra: 819 GB/s (3)
- Nvidia RTX 4070: 504,2 GB/s (4)
- Nvidia RTX 5090: 1.790 GB/s (5)
- PC mit RAM DDR5-4800: 51,6 GB/s (6)
Wie zu sehen ist, ist RAM in einem aktuellen PC viel langsamer als in den fortschrittlichsten Apple -Chips. Der Mac Mini M4, den ich in den Tests verwendet habe, ist nicht besonders bemerkenswert, aber die Bandbreite seines Gedächtnisses ist doppelt so hoch wie bei DDR5-4800-Modulen. Hier haben wir übrigens oben erwähnt, dass wir unseren «lokalen Chatgpt» verwendet haben, um ein Diagramm aus einem kleinen Code in Python zu generieren. Das Ergebnis, ohne besonders farbenfroh zu sein, ist funktional und korrekt.
Letztendlich besteht die Idee nach dem Diagramm genau darin, das Wichtigste bei der Ausführung lokaler KI -Modelle widerzuspiegeln. Die GPU und die NPU helfen sicherlich sehr, aber der Schlüssel ist in 1) Wie viel grafischer Speicher haben wir und 2) Welche Bandbreite hat dieser grafische Speicher?. Und in beiden Fällen, desto viel besser, besonders wenn wir zu Hause schwere Modelle durchführen wollen, Etwas, das sehr, sehr teuer machen kann.
Das GPT-OS-120B-Modell würde beispielsweise mindestens 80 GB Grafikspeicher erfordern, und es gibt nicht viele Teams, die so etwas aufweisen können: Hier ist das einheitliche Apple-Speicherschema vorerst eine Option, da die Alternative darin besteht, eine oder mehrere dedizierte Hochwertegrafiken mit niedriger Fenstern oder Linux-Easel zu verwenden.
Das heißt, es wird interessant sein zu sehen, wo sich diese Modelle bewegt. Die Aussage, dass das kleinste Modell (GPT-OSS-20B) in Mobiltelefonen verwendet werden kann, ist etwas Riskantes, aber nicht verrücktes: Mit einer angemessenen Konfiguration der Ausführungsschicht (Ollama, LM Studio oder der entsprechenden mobilen App) scheint es perfekt möglich, dass wir lokales Chatpt auf unserem Mobilfunk führen können.
Eine, die es all unseren Daten ermöglicht, nicht zu verlassen (Datenschutz nach Flag) und es uns auch ermöglicht, Kosten zu sparen. Die Zukunft der lokalen KI eröffnet jetzt mehr denn jeund wir hoffen nur, dass dies ein Trend für andere Unternehmen wird, die offene Modelle entwickeln. Dieser von Openai ist zweifellos ein großartiger und vielversprechender Schritt für die zukünftige Theoretik, in der wir Modelle der massiven Ausführung auf unseren PCs, in unseren Handys oder in unserer Brille haben.
In | Ziel hat einen hervorragenden Grund, eine gigantische Flamme -Variante 4: Spezialisierungskapazität zu starten












{kind=link}